Reinforcement Learning to Enable Robust Robotic Model Predictive Control
Abstract
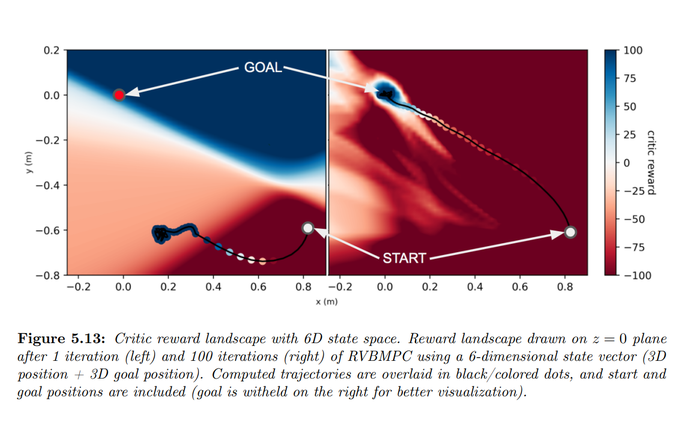
Traditional methods of robotic planning and trajectory optimization often break down when environmental conditions change, real-world noise is introduced, or when rewards become sparse. Consequently, much of the work involved in calculating trajectories is done not by algorithms, but by hand - tuning cost functions and engineering rewards. This thesis seeks to minimize this human effort by building on prior work combining both model-based and modelfree methods within an actor-critic framework. This specific synergy allows for the automatic learning of cost functions expressive enough to enable robust robotic planning. This thesis proposes a novel algorithm, “Reference-Guided, Value-Based MPC,” which combines model predictive control (MPC) and reinforcement learning (RL) to compute feasible trajectories for a robotic arm. The algorithm does this while 1) achieving an almost 50% higher planning success rate than standard MPC, 2) solving in sparse environments considered unsolvable by current state of the art algorithms, and 3) generalizing its solutions to different environment initializations.